ODroid xu4 Ubuntu 18.04 Download
Download page: https://odroid.in/ubuntu_18.04lts/XU3_XU4_MC1_HC1_HC2/
Minimal install Image: ubuntu-18.04.1-4.14-minimal-odroid-xu4-20181203.img.xz
RiSCV Development Hardware
AMD Product Names make no sense
More than anything this post will demonstrate my ignorance to anyone with a passing familiarity with consumer hardware, but my current grievance with AMD is that their GPU names don’t make any sense. One thing that AMD has done in the last two years in make a comeback in the CPU department, and I think a large reason for that is they’ve done a great job of simplification and branding. One thing that Intel did really well was their product naming, they had their Atom, Pentium/Celeron, Core and Xeon lines. You knew, and could get an idea from the names that atom was for low end, low power, Celeron was low end, Pentium slightly better, core professional and then Xeon was for servers. With AMD, I can’t even remember what most of the names where. “Pheanom”, or “Opertron”? And I don’t even know which level these were intended for. I think with their APU lines, they cleaned a lot of this up with their “A6”, “A8” naming.
One thing Ryzen did is it made it really easy to understand which models do what. You have the Ryzen R3, R5, and R7, and then you have the series so Ryzen 1000, 2000, 3000 for each generation. It makes it easy to know what you want and what model you’re looking for when buying a CPU. It’s still rumored, but AMD’s navi line of GPU’s could be coming out in a few months, and I hope their marketing department does the same thing they did for Ryzen to their GPU line. Because as bad as AMD’s CPUs were in terms of naming, their GPU’s are pretty bad or potentially even worse.
What do I mean by that? The Radeon VII. What the fuck kind of name is that? It’s named “VII” because it’s based on the 7nm process. Well is the “Nano R9” named that because it’s on the 9nm process? You have the RX series, which you have the 570, 580 and 590. Except the 590 is just an over clocked 580. And all of these cards are pretty much overclocked versions of the previous 4xx series. And then you have these other random cards like, “Vega”, “R9” and the “VII” in there. And what the hell came before the RX400 series? Oh right, the Radeon 5000 series (i think). None of this makes any freaking sense. One thing I hope AMD does is find a consistent naming convention for their GPU’s and stick with it.
Piboy Advance Mockup
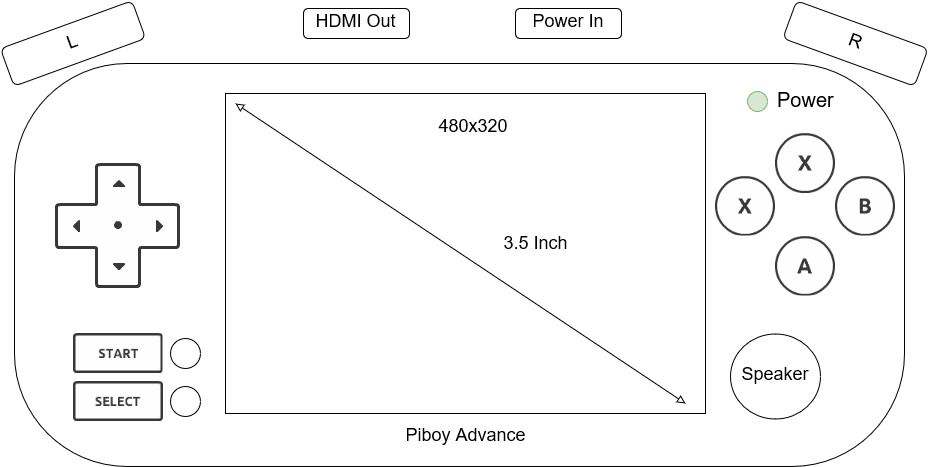
While I have no idea how to put hardware together, I’ve been putting more thought into standardized Pi hardware that can be used as a development platform. For the Piboy advance, I’ve made the following drawing of the resolution and inputs. Specifically the hardware uses a 3.5 inch 480×320 inch screen, with a dpad, right and left buttons, four face buttons and two buttons for start / select. Though in practice, these would be better labeled as “Pause” and “Home”.
Not pictured is the on and off button, (which would probably be under the left hand side of the device), or the volume slider (which would probably be on the right hand side of the device). And video out and power in, would be placed on the top of the device, so it could be charged while be used, and the output could be sent to a larger screen.
Ubuntu 18.04 OSM
After switching from Debian to Ubuntu, the results so far have been inconclusive. I was able to install postgres, download and import the map data, make and install mapnik. And after attempting to install mod tile, I simply end up with the error:
debug: init_storage_backend: initialising file storage backend at: /var/lib/mod_tile
In the apache error file. However, no tiles are ever generated. Since I think most of the pieces are in place I’m going to go ahead and attempt to fiddle with what’s there and try to get something working. I can try initializing the renderd process from the command line to be able to track the output. I can try generating tiles from the command line to see if mapnik is working. And I can try to re-import the data, which I am currently running at the moment. So I think it’s a matter of testing the variables and seeing what works.
sudo apt-get install postgresql postgresql-contrib postgis postgresql-10-postgis-2.4 \ postgresql-10-postgis-scripts osm2pgsql git autoconf libtool libmapnik-dev apache2-dev
Debug
Okay I found the issue. By looking at ‘systemctl status renderd’ we get the following error.
Received request for map layer 'default' which failed to load
Which looks like the style.xml file doesn’t exist. So the following step is failing.
carto project.mml > style.xml
So the way to fix this was to install carto and then call it publicly.
sudo apt-get install npm sudo npm install carto -g /usr/local/lib/node_modules/carto/bin/carto project.mml > style.xml
Okay then we try: http://192.168.179.21/osm_tiles/0/0/0.png

Follow Up
So here is my index.html file:
<!DOCTYPE html>
<html>
<head>
<title>Quick Start - Leaflet</title>
<meta charset="utf-8" />
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<link rel="shortcut icon" type="image/x-icon" href="docs/images/favicon.ico" />
<link rel="stylesheet" href="https://unpkg.com/leaflet@1.4.0/dist/leaflet.css" integrity="sha512-puBpdR0798OZvTTbP4A8Ix/l+A4dHDD0DGqYW6RQ+9jxkRFclaxxQb/SJAWZfWAkuyeQUytO7+7N4QKrDh+drA==" crossorigin=""/>
<script src="https://unpkg.com/leaflet@1.4.0/dist/leaflet.js" integrity="sha512-QVftwZFqvtRNi0ZyCtsznlKSWOStnDORoefr1enyq5mVL4tmKB3S/EnC3rRJcxCPavG10IcrVGSmPh6Qw5lwrg==" crossorigin=""></script>
</head>
<body>
<div id="mapid" style="width: 600px; height: 400px;"></div>
<script>
var mymap = L.map('mapid').setView([35.145844, 138.681230], 2);
L.tileLayer('/osm_tiles/{z}/{x}/{y}.png', {
maxZoom: 18,
attribution: 'Map data © <a href="https://www.openstreetmap.org/">OpenStreetMap</a> contributors, ' +
'<a href="https://creativecommons.org/licenses/by-sa/2.0/">CC-BY-SA</a>, ' +
'Imagery © <a href="https://www.mapbox.com/">Mapbox</a>',
id: 'mapbox.streets'
}).addTo(mymap);
</script>
</body>
</html>
And here’s what the result looks like:
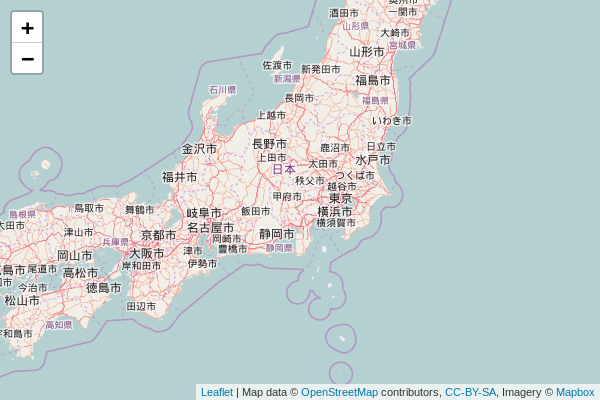
I had to increase the tile missing timeout from 30 seconds to 60 seconds. The result is painfully slow, so it’s not exactly viable, but it is possible. I think the SD card is likely a huge bottleneck for the database read-write speeds. I’m going to go ahead and say that this is confirmed, you can make a tile server on an SD card based ARM SoC, but you probably wouldn’t want to. Something like the Rock Pi 4 that has an nVme SSD connector would likely make a better test candidate.
Libreboard OSM
Abstract
With the popularity of the Raspberry Pi, combined with the Raspberry Pi Foundations unwillingness to distribute more powerful hardware, there are a lot of board makers coming out with more and more powerful system on a chip computers to try and fill the void, and market, left by the Raspberry Pi. One of these makers is Libre Compters, and the Specific board I’m using is the ROC-RK3328-CC running Debian. Links for the hardware and Linux distribution can be found below.
Libre Computer: https://libre.computer/products/boards/roc-rk3328-cc/
Roc Documentation: https://roc-rk3328-cc.readthedocs.io/en/latest/intro.html
Debian: http://download.t-firefly.com/Source/RK3328/ROC-RK3328-CC/Firmware/Debian/ROC-RK3328-CC_Debian9-Arch64_20180525.img.xz
I personally got my hands on the 4GB version, and have the operating system installed on a 64GB SD card. I’d prefer to either have the eMMC card, but can’t seem to find a reasonably priced version from the stores available to me, or I’d like the option to boot from an external hard drive or SSD, but can’t find if this is supporter or not. Though specifically what I wanted to test is with more powerful ARM devices coming out, is it possible to install something like an Open Street Map tile server, to be able to serve regional maps from an SoC?
The source for this install is taken from https://itsolutiondesign.wordpress.com/2017/07/11/build-your-own-openstreetmap-tile-server-on-ubuntu-16-04/, and has been copied to “show my work” on what specific commands are being executed in what order.
Install PostGres
$ sudo apt install postgresql postgresql-contrib postgis postgresql-9.6-postgis-2.3 postgresql-9.6-postgis-scripts
Create Postgres Database
sudo -u postgres -i createuser osm createdb -E UTF8 -O osm gis psql -c "CREATE EXTENSION hstore;" -d gis psql -c "CREATE EXTENSION postgis;" -d gis exit
Create OSM user and download map data
sudo adduser osm su - osm cd wget https://github.com/gravitystorm/openstreetmap-carto/archive/v2.41.0.tar.gz tar xvf v2.41.0.tar.gz $ rm v2.41.0.tar.gz $ wget -c http://download.geofabrik.de/asia/japan-latest.osm.pbf exit
Create swap file (to prepare for import)
sudo dd if=/dev/zero of=/swapfile bs=1GB count=2 sudo chmod 600 /swapfile sudo mkswap /swapfile sudo swapon /swapfile
Import map data
sudo apt-get install screen osm2pgsql su - osm osm2pgsql --slim -d gis -C 3600 --hstore -S openstreetmap-carto-2.41.0/openstreetmap-carto.style japan-latest.osm.pbf exit
And this is where my experiment came to an end. This process takes a long time even with more powerful systems, so I let the import run during the day. And when I got home at night, I found that the ROC-RK3328-CC was no longer available on the network. After rebooting the system, I would try to continue the process only to find that for some reason the SD card was now mounted as read-only, and I didn’t have any luck in mounting the SD card as read-write. I tried to reflash the SD card with Debian, and tried the process two more times and ended up with the same result.
I’m not sure if this is something done on my end, such as using a power supply that could not sustain the board for an extended period of time. I’m not sure if the board requires some manner of active cooling. I’m not sure if this is a bug in their compiled version of Debian, but at this point the process became frustrating enough that I would try their Ubuntu image option and only return to Debian if that proved successful.
Static Dash Format
Header
| DASH | v1 | IMG num | ofs |
| TEX num | ofs | MAT num | ofs |
| VERT num | ofs | FACE num | ofs |
| BONE num | ofs | ANIM num | ofs |
Images
| IMG id | type | offset | length | width | height |
Textures
| TEX id | IMG id | wrap S | wrap T | flipY |
Materials
| MAT id | TEX id | use blend | blend src | dst | opacity 0.0 – 1.0 |
| transparent | visible | vertex color bool | skinning bool | side const |
| diffuse red 0.0 – 1.0 | diffuse green 0.0 – 1.0 | diffuse blue 0.0 – 1.0 | diffuse alpha 0.0 – 1.0 |
Vertices
| position x | position y | position z | index 0 | index 1 |
| index 2 | index 3 | weight 0 | weight 1 | weight 2 |
| weight 3 |
Faces
| MAT id | a index | b index | c index | a color | b color |
| c color | a normal x | a normal y | a normal z |
| b normal x | b normal y | b normal z | c normal x |
| b normal y | b normal z | a texture u | a texture v |
| b texture u | b texture v | c texture u | c texture v |
Bones
| bone id | parent id | position x | position y | position z |
| rotation x | rotation y | rotation z | scale x |
| scale y | scale z |
Anims
| Anim id | num frames | offset | length | time |
Anim Format
| Frame id | Bone id | time | pos | rot | scale | position x |
| position y | position z | rotation x | rotation y |
| rotation z | rotation w | scale x | scale y |
| scale z |
Balancing the Model Layout
So one thing that I can’t get my brain around is around is how to balance the Dash Model format. Specifically with respect from the file body to the file header. I have a couple of options in front of me. By far the easiest option would be to implement the file type in blocks. And in that situation you would create an Image block, that image block would contain all of the information for images, and then you would move on to the texture block, which would do the same for the textures. In general one of the designs that I’m working around is that I want the top of the file to act as a summary of the tile. So if someone read the top of the file they should get an idea of how many vertices, faces, animations and images are in the file.
But then what happens is that you have to manage how much information to put in the header versus the body. You can create a super tiny header and include the rest of the information in the body, or you can put some of the information (like names) in the header and have the body be nothing but structs, or you can simply have nothing but blocks where all of the data is defined in a list one right after the other. Though right now I think it might be easier to define the file format as blocks, include all of the information that I think is required to implement each block, and then there I can think about to balance the information between the header and blocks.
Quick Summary of the Properties:
Meta
Author
License
Created on
Exported By
Image
Image Id
Image Name
Image Data
Texture
Texture Id
Texture Name
Image Id
Wrap S/T
flipY
Materials
Material Id
Material Name
Texture Id (-1 for none)
Diffuse Color
Skinning?
Mostly Minified Version
DASH v1 OFS LEN AUTH LEN [ ] COPY LEN [ ] DATE LEN [ ] TOOL LEN [ ] IMG NUM OFS SIZE [ id png ofs len ] [ id png ofs len ] [ id png ofs len ] TEX NUM OFS SIZE MAT NUM OFS SIZE VERT NUM OFS SIZE FACE NUM OFS SIZE BONE NUM OFS SIZE ANIM NUM OFS SIZE [ id time ofs len ] [ id time ofs len ] [ id time ofs len ] [ id time ofs len ]
Fully Minified Version
DASH VER OFS SIZE AUTH NUM OFS SIZE COPY NUM OFS SIZE DATE NUM OFS SIZE TOOL NUM OFS SIZE IMG NUM OFS SIZE TEX NUM OFS SIZE MAT NUM OFS SIZE VERT NUM OFS SIZE FACE NUM OFS SIZE BONE NUM OFS SIZE ANIM NUM OFS SIZE
Designing the Dash Model Format
Since we have the FBX SDK working, then the next step is to start working on the next piece, which is designing the Dash Model Format. Specifically I’m aware that GLTF is a thing, but it’s an over complicated format, and not something that I really want to work with myself. And in a lot of cases I’m finding that I’m going in the opposite direction of everyone else that seems to view threejs as a deployment target at the end of production, where as I’m using threejs for reading models and trying to get them back into a usable format.
So I’ll start with the pieces that I’m pretty confident about and then try to fill in-between or mark out areas that are unclear. So the first part that’s easy is the magic number at the beginning of the file. To be able to check if a file is a Dash Model file or not, the first four bytes of the file should start with “DASH”, and then be followed by the version number. In general my plans for the Dash Model format is a very specific set of models to specifically be able to accurately describe models that were created in the 1990’s to 2000’s, so there could be a lot of modern techniques that I’m missing out on. I don’t want to make anything that tried to support everything and gets over-bloated, but I do want to leave myself some flexibility to allow the format to be expanded or adjusted without breaking compatibility if possible. So following DASH, my plan is to put the version number, which can either be a uint32 value of either “1, 2, 3, ect”, or maybe even a string value of “v1.0”, “v2.1”, ect. And I’m leaning toward the string version as it seems more descriptive.
The next step is to start working on the values that I want, or need to record. The general areas are pretty straightforward.
– Images
– Textures
– Materials
– Vertices (skin weights, and skin indexes)
– Faces (indices, texture coords, face vertex colors, material index, face normals)
– Bones
– Animations
So there’s really only one “easy” design decision in here, and that’s to have the face handle vertex colors and face normals as opposed to storing them with the vertices, and it’s easier to think of a unique vertex as a unique point with a unique weight. Though honestly, even that is debate-able. From there I have a few general questions to contend with:
1) Do I separate between Meshes and Skinned meshes?
2) For weights do I allow for setting the number of weights, or do I assume a maximum of 4?
3) How do I set the format for faces?
4) Do I support shaders?
5) Do I support more than 1 uv channel?
And right now my thoughts are:
1) I don’t think I need to separate between skinned and non-skinned meshes and just assume everything is technically a skinned mesh, except when it’s not. So models that don’t have bones will just have zero bones, zero animations, and zero weight.
2) For weights, one the idea is to save space on file size using binary, so I think I can afford to use weights. And second most of what this file format is intended for is working with characters. But at the same time it would be pretty stupid to export stages (which have a large number of vertices) with vertex weights. But at the same time, since these won’t have animations, the file size should balance out. So a skinned or not flag could be beneficial, but if I want to make the format as static as possible, then I would just include weights in all cases.
3) For face format, this raises several questions. Do I allow for different face types to be defined (ie by defining a byte with bit flags), or do I define a create a flag that is set for a group of faces. And if I do that would I would have to allow for multiple face groups, or would I force one type for the entire model? Again this goes with vertices, but if I want to make the file format as static as possible, then inserting default values when these are not set would make things simple, as that’s generally want the editor or viewer is doing in the background anyway.
4) For now, I think no. Even if I define shaders, it’s not something that is supported by a lot of editors. So I think that sticking with a standard format makes more sense.
5) Again, no. I don’t have enough experience with multiple uv channels, and all of the models I’ve worked with, and that I’m targeting for this format only have one uv, channel, so I’m not going to try to support something I’m not familiar with. So for vertices, and faces I have the following format:
Vertices
[ x (4) float ] [ y (4) float ] [ z (4) float ]
[ indicex (2) ushort ] [ indicey (2) ushort ] [ indicez (2) ushort ] [ indicew (2) ushort ]
[ weightx (4) float ] [ weighty (4) float ] [ weightz (4) float ] [ weightw (4) float ]
Faces
[ material index (2) ushort ]
[ a (2) ushort ] [ b (2) ushort ] [ c (2) ushort ]
[ aColor (4) uchar[4] ] [ bColor (4) uchar[4] ] [ cColor (4) uchar[4] ]
[ aNormal (12) float[3] ] [ bNormal (12) float[3] ] [ cNormal (12) float[3] ]
[ aTexture (8) float[2] ] [ bTexture (8) float[2] ] [ cTexture (8) float[2] ]
The next structure to start working on is bones. For bones, there is a lot of information that we have the option of either including or not including. A quick sketch of what I have in mind currently is the following:
[ Bone Name (0x20) char[0x20] ]
[ Bone Id (2) ushort ] [ Parent Bone Id (2) ushort ]
[ Position (12) float[3] ]
[ Rotation (16) float[4] ]
[ Scale (12) float[3] ]
[ Matrix (0x40) float[16] ]
[ Inverse Matrix (0x40) float[16] ]
Though I have several issues with this. For starters having the bone name floating about the struct looks kind of dumb, but I think in this format, we have images and animations that will have names as well. So I’m not sure if I want to have the names floating, or declare the id before the name. Declaring the id first is going in look better in general, even if it makes the string length 0x28 instead of 0x20, which shouldn’t really be an issue.
For rotation we have the option of using either quaternions or euler angles. I don’t think we have to worry about gimbol lock with bones, so normal euler angles are probably going to be better to work with.
From there we have the Matrix and inverse matrix. Looking at it, the matrix looks pretty stupid. Originally I would just want the matrix (and potentially inverse matrix), but I know some importers want the individual position rotation and scale, so I can probably take this out.
And for the inverse matrix, i’m not sure if this is the best to place to put it. The values provided could be wrong, so calculating them on import might be the easiest way, since I’ll probably have to figure out how to calculate them sometime eventually. But basically we can trust the transformations, and that someone could write these, but probably not the inverse matrix. So what we end up with is:
[ Bone Id (2) ushort ] [ Parent Bone Id (2) ushort ]
[ Bone Name (0x20) char[0x20] ]
[ Position (12) float[3] ]
[ Rotation (12) float[3] ]
[ Scale (12) float[3] ]
Which looks stupid, because it looks I’ll have NOPS everywhere to make the spacing align the struct to increments of 0x10 to make it easier to work with. This is why I originally just wanted matrix and inverse matrix, but generating matrices is easier than extracting them. Also I should go ahead and check to see which editors generate (and require) inverse matrices, because if editors have the values when exporting then might as well pop them in there.
Though I could reorganize the struct to
[ Bone Id (2) ushort ] [ Parent Bone Id (2) ushort ]
[ Position (12) float[3] ]
[ Rotation (12) float[3] ]
[ Scale (12) float[3] ]
[ Bone Name (0x20) char[0x28] ]
To align the struct to fit sizes of 0x10. Though I don’t think I did this with vertices or faces, so I can probably ignore this constraint and implement what’s easiest, but for bones, it seems like a good idea to make them easy to read (visually). Though I think a lot of that has to do with the string being declared inside the struct, if I declare the string in the header (like an archive), then I can just declare position, rotation, scale in the body of the file (though matrix and inverse matrix would be more elegant). Easiest option seems to be to throw bone names under the bus.
Which means right now my file header looks something like this:

Which I’m actually liking declaring the names in the header, so doing the same with materials and textures might make it look more clean. And since the size of the header isn’t fixed, i should add offset and length in the first line of the file. Which makes the face list and vertex list the odd members here since everything else has a name. I’m tempted to use the space to declare the format for the vertices and faces. Also the extended letters for the labels look stupid, i should keep those to a magic number.